
1. 前言
在Spring WebFlux项目中,WebClient将调用特定的AI服务并获取其返回的数据流。系统会依据数据流中首个响应的类型,将数据流分发至不同的处理模块(例如音频、文本、图像等)。各模块处理完成后,数据流将被合并并返回给客户端以供渲染。在此过程中,通share()操作将数据流共享至后端多个业务流进行处理,避免WebClient重复调用大模型,从而提高系统的效率和性能。
示例代码如下所示:
var aiModelFlux = generateStream()
.doOnSubscribe(subscription -> log.info("Ai能力被订阅: {}", subscription))
.share();
var res = aiModelFlux
.next()
.doFinally(signal -> log.info("响应分类处理结束: {}", signal))
.flatMapMany(data -> dispatchStream(aiModelFlux));
res.subscribe(data -> {
// 业务处理,略
});其中dispatchStream函数示例如下所示:
public Flux<String> dispatchStream(Flux<AIResponseTransitDTO> aiAnswerStream) {
return Flux
.concat(
aiAnswerStream
.filter(response -> response.getCategory().equals(TEXT))
.map(response -> {
// 处理文本响应
return response.getData() + "1";
}
),
aiAnswerStream
.filter(response -> response.getCategory().equals(TEXT))
.map(response -> {
// 处理文本响应
return response.getData() + "2";
}
)
)
.doFinally(signal -> log.info("分发数据流处理结束: {}", signal));
}2. WebClient重复执行
2.1 日志
在测试过程中,我们发现尽aiModelFlux已经执行share()操作,理论上第一次调用产生的数据流应被多个订阅者共享,但实际上WebClient却多次调用了AI模型。相关日志如下所示:
-- Ai能力被订阅: reactor.core.publisher.SerializedSubscriber@71a3a190
-- 连接建立成功: GET{uri=/, connection=PooledConnection{channel=[id: 0x436eb4d1, L:/192.168.103.4:5525 - R:/192.168.32.103:6061]}}
-- Ai能力被订阅: reactor.core.publisher.SerializedSubscriber@23f862bc
-- 响应分类处理结束: onComplete
-- 连接建立成功: GET{uri=/, connection=PooledConnection{channel=[id: 0xb7812d81, L:/192.168.103.4:5526 - R:/192.168.32.103:6061]}}
-- Ai能力被订阅: reactor.core.publisher.SerializedSubscriber@22e134c0
-- 连接建立成功: GET{uri=/, connection=PooledConnection{channel=[id: 0xbfa8add4, L:/192.168.103.4:5529 - R:/192.168.32.103:6061]}}
-- 分发数据流处理结束: onComplete查看share()函数定义:
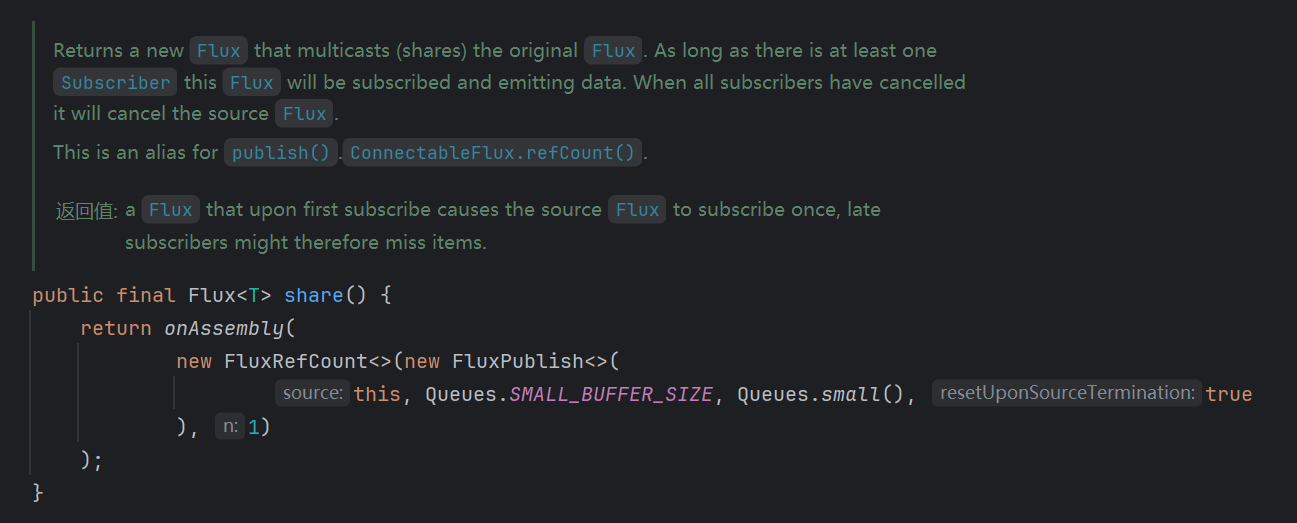
2.2 订阅关系
观察前序章节日志,可以发现示例代码产生了三次订阅,经过梳理三次订阅分别如下所示:
(1)第一处调用:
var res = aiModelFlux
.next() // 第一处订阅
.doFinally(signal -> log.info("响应分类处理结束: {}", signal));next操作是订阅操作,其特殊性在于只订阅数据流的第一个元素。
(2)第二、三处订阅
res.subscribe(data -> {
// 第二、三处订阅
});这里令人困惑的地方在于,尽管代码中只调用了一次subscribe,aiModelFlux实际上却被订阅了两次。原因在dispatchStream函数aiModelFlux进行了处理,生成了两条新的数据流,并进行concat操作。虽concat确保了新数据流的顺序,但它也导aiModelFlux无法被同时订阅share失效),而是被依次订阅。
若dispatchStream函数中Flux.concat改Flux.merge ,则aiModelFlux.share操作大概率生效,即只会被订阅一次(前提是两条业务流能够近乎同时执行)。
3. 修改方案
根据分析,数据流在执share操作后,是否能被共享取决于后续消费者的执行时机。如果后续业务流能够近乎同时启动,则数据流可以被共享;反之,若业务流存在较大延迟,近乎串行执行,则会导致数据流重复触发。
为避免WebClient重复调用AI能力并实现数据流共享,可改cache操作符替share。
示例代码如下所示:
var aiModelFlux = generateStream()
.doOnSubscribe(subscription -> log.info("cache: Ai能力被订阅: {}", subscription))
.cache();
var res = aiModelFlux
.next()
.doFinally(signal -> log.info("cache: 响应分类处理结束: {}", signal))
.flatMapMany(data -> dispatchStream(aiModelFlux));
res.subscribe(data -> {
// 丢弃数据,不做处理
});日志如下所示:
-- cache: Ai能力被订阅: reactor.core.publisher.SerializedSubscriber@7c211fd0
-- 连接建立成功: GET{uri=/, connection=PooledConnection{channel=[id: 0x95beb124, L:/192.168.103.4:8637 - R:/192.168.32.103:6061]}}
-- cache: 响应分类处理结束: onComplete
-- 分发数据流处理结束: onComplete