
1. 前言
近期在验收厂商提交的功能时,发现某SQL执行存在严重性能问题。初期判断可能因测试环境MySQL配置较低且涉及多表JOIN,故未深究。
但随着测试深入,该SQL执行耗时远超可接受阈值,异常延迟引起警觉,随即启动专项排查。
2. 分析
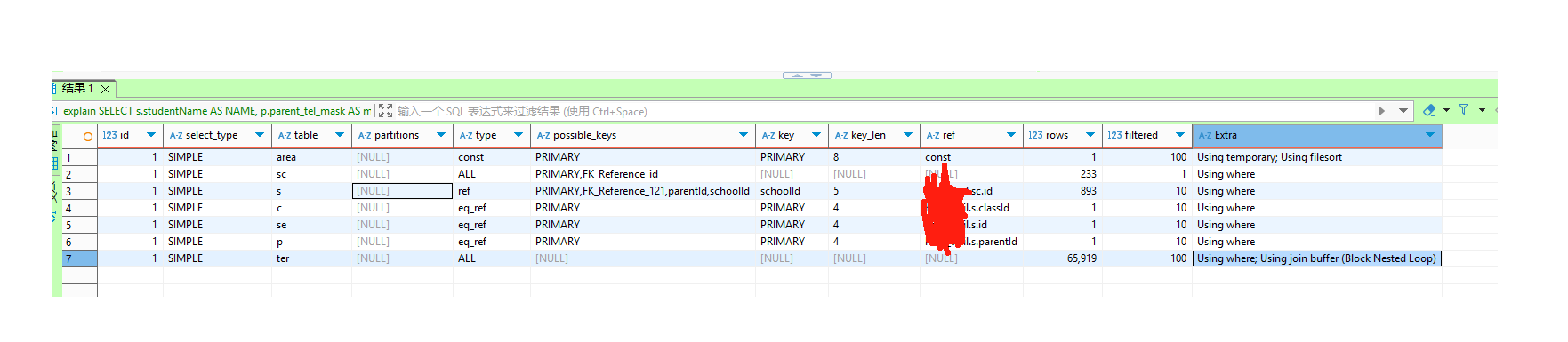
执行 EXPLAIN 分析后发现,驱动表 ter 的 JOIN 操作存在严重性能异常:未触发索引访问,而是强制执行了全表扫描。
type: ALL- 全表扫描(最严重问题)key: NULL- 未使用任何索引Extra: Using where; Using join buffer (Block Nested Loop)❗ 关键问题:未使用
teno主键索引使用缓冲区进行批量查询
让人困惑的点在于,ter的join关键字是varchar类型的主键(历史设计)。
比对数据表的DDL,发现:
字符集不一致:一张表是
utf8,一张表是utf8mb4;排序规则不一致:一张表是
utf8_general_ci,而另外一张表是utf8_bin。
3. 原因
因历史SQL均在各自数据库内部执行,未涉及跨库联表操作,故该性能问题始终未被察觉。
此次为提取运营数据,首次实施跨库查询方案。在大数据量场景下,此潜在性能瓶颈终暴露显现。
现提供排查SQL,可识别当前库内字符集与排序规则未统一的数据表及对应字段:
SELECT
TABLE_SCHEMA AS `数据库`,
TABLE_NAME AS `表名`,
COLUMN_NAME AS `字段名`,
COLUMN_TYPE AS `字段类型`,
CHARACTER_SET_NAME AS `字符集`,
COLLATION_NAME AS `排序规则`,
CHARACTER_MAXIMUM_LENGTH AS `最大长度`
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = 'XXXX' -- 替换为你的数据库名
AND DATA_TYPE IN ('varchar', 'char', 'text', 'tinytext', 'mediumtext', 'longtext')
AND CHARACTER_SET_NAME != 'utf8mb4' AND COLLATION_NAME !='utf8mb4_bin'
ORDER BY TABLE_NAME, ORDINAL_POSITION;