
1.前言
近期看博文《技术分享 | MySQL 生产环境 GROUP BY 优化实践》,发现对于项目上的GROUP BY操作,可以基于松散索引扫描(Loose Index Scan)进行优化。
本文仅作简单摘录及总结,具体原理详见博文。
2. 基本概念
2.1 GROUP BY条件有无索引
对于 GROUP BY 在使用索引上的优化,分为两种情况讨论:
表上无索引。执行时,会生成临时表进行分组。可以通过索引来优化,来避免使用临时表。
表上有索引。 GROUP BY 语句有几种扫描算法:
松散索引扫描(Loose Index Scan)
紧凑索引扫描(Tight Index Scan)
两种算法结合。
2.2 松散索引扫描(Loose Index Scan)
原理:跳跃扫描部分索引,而不需要扫描全部。
Explain关键词:Using index for group-by。
以下是示意图:
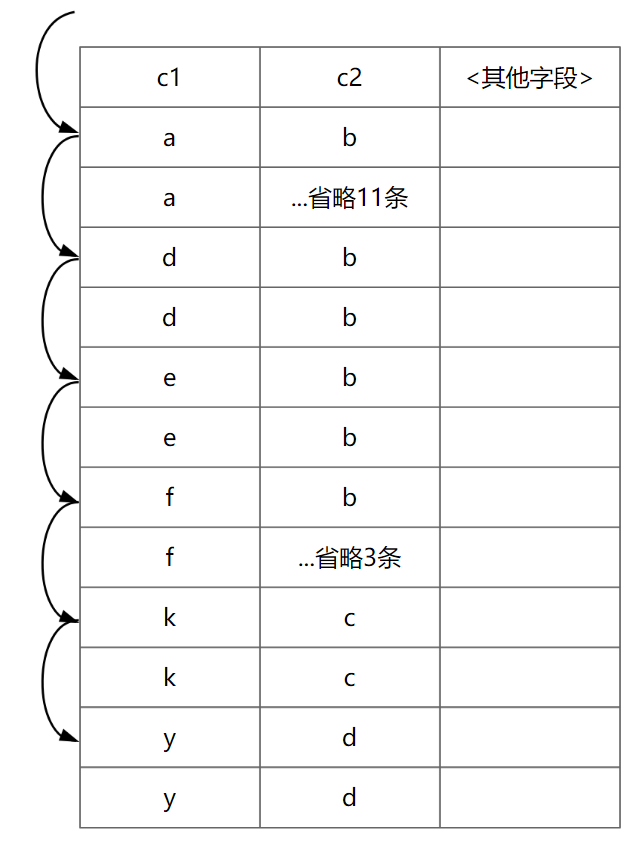
使用松散索引扫描,适用于对分组数据(具有大量的重复值),执行MIN/MAX等提取极值的操作。
使用条件较为苛刻,即GROUP BY需落在索引上,执行的MIN/MAX/COUNT等操作涉及的字段,也需在索引上(注意,可以不是GROUP BY涉及列所属索引)。
2.3 紧凑索引扫描(Tight Index Scan)
原理:需要扫描范围或全部的索引。
Explain关键词:Using index。
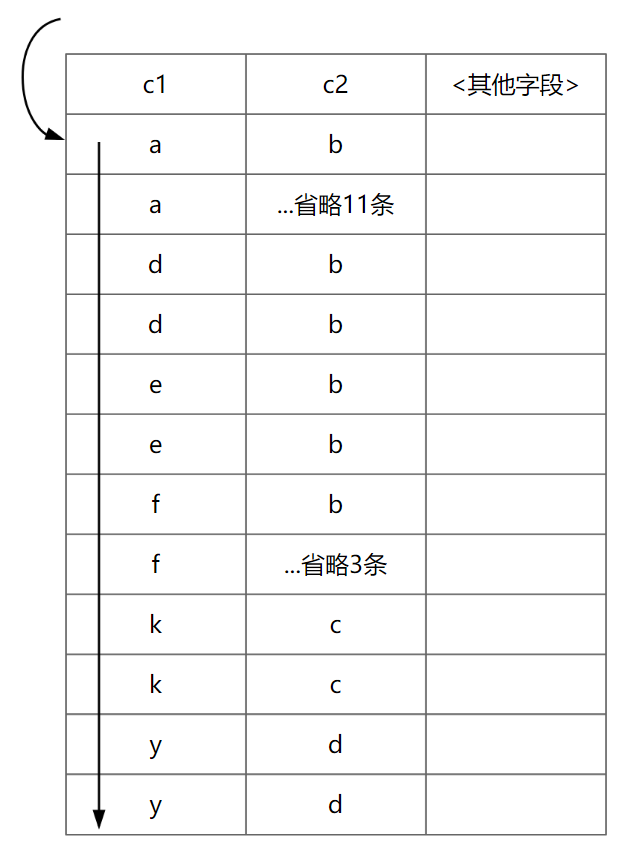
从上图可知,在一般场景中,使用紧凑索引扫描进行GROUP BY操作,其效率会较差。
但是在分组数据较多,且组内的记录数不多或者唯一值较高的场景下,紧凑索引扫描(Tight Index Scan)的扫描效率要比松散索引扫描(Loose Index Scan)高。
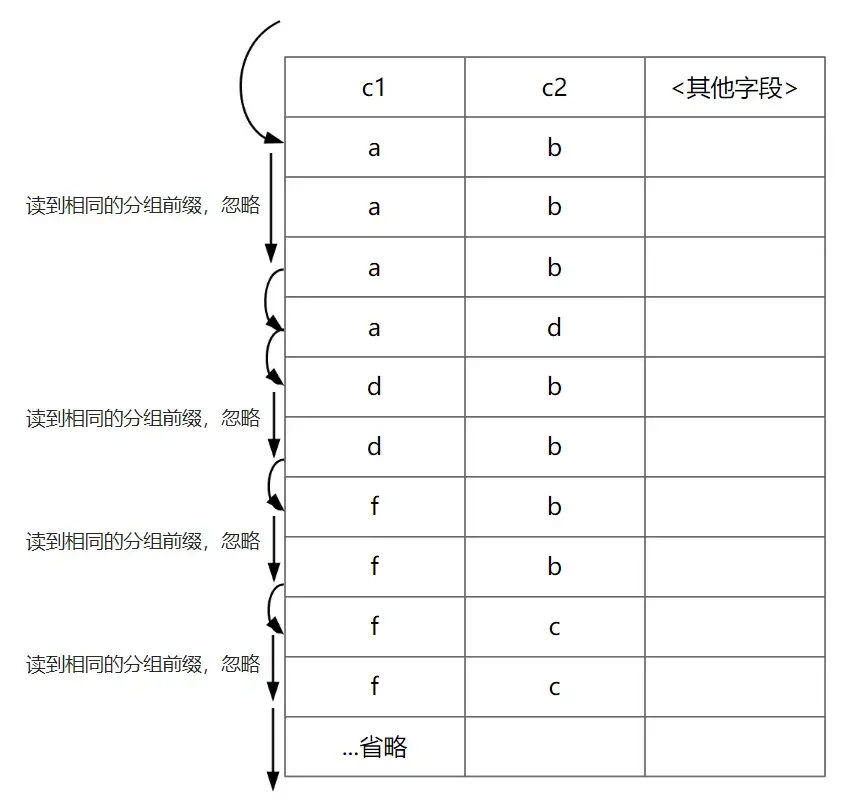
2.4 Loose Index Scan扩展
原理:索引顺序扫描的同时进行去重。
Explain关键词:Using index for group-by (scanning)
以下是示意图:
3. 应用
博文中提及了一个生产案例,能知晓为何就基本理解概念了:
改进前SQL:
SELECT a.taskUniqueId,
reportTime
FROM task_log_info a
JOIN
(SELECT taskUniqueId,
max(id) AS id
FROM task_log_info
GROUP BY taskUniqueId ) tmp
ON a.id=tmp.id
AND reportTime>='2024-04-07'改进后SQL:
SELECT a.taskUniqueId,
reportTime
FROM task_log_info a
JOIN
(SELECT taskUniqueId,
max(id) AS id
FROM task_log_info
GROUP BY taskUniqueId ) tmp
ON a.id=tmp.id
AND reportTime>='2024-04-07'个人觉得示例中使用reportTime不太合适,替换为createTime更为合适(id和createTime的关系更加显著)。
详细答案可见原始博文。