
背景与测试动机
最近发现Spring Cloud Gateway推出了spring-cloud-starter-gateway-server-webmvc模块,大抵是因为虚拟线程(Virtual Threads)的引入,带来了新的性能和并发模型选择。因此就想尝试一下WebFlux和WebMVC两种实现方式在实际性能上的差异。
WebFlux的编程模型掌握起来较为复杂,存在两点问题:
学习心智负担较高,处理异常、数据共享等不如同步模式直观。
相关依赖需要适配Reactor 模式,但相应生态发展较为滞后(例如R2DBC等)。
因此在未来,WebMVC + 虚拟线程可能是一个值得探索的选择。
1. 部署架构与测试环境
1.1 技术栈
Java 版本: Amazon Corretto 25.0.1(Java 25)
Spring Boot: 4.0.0
Spring Cloud Gateway: 5.0.0
WebFlux:
spring-cloud-starter-gateway-server-webflux(Reactor Netty)WebMVC:
spring-cloud-starter-gateway-server-webmvc(Tomcat)
容器: Docker with Amazon Corretto 25.0.1
虚拟线程: 所有后端服务均开启虚拟线程(
spring.threads.virtual.enabled=true)JVM 参数:
网关WebFlux:
-Xms2g -Xmx2g网关WebMVC:
-Xms2g -Xmx2gGC策略: 使用Java 25默认GC
无额外调优参数(未显式配置GC线程数、超时时间等)
1.2 部署架构图
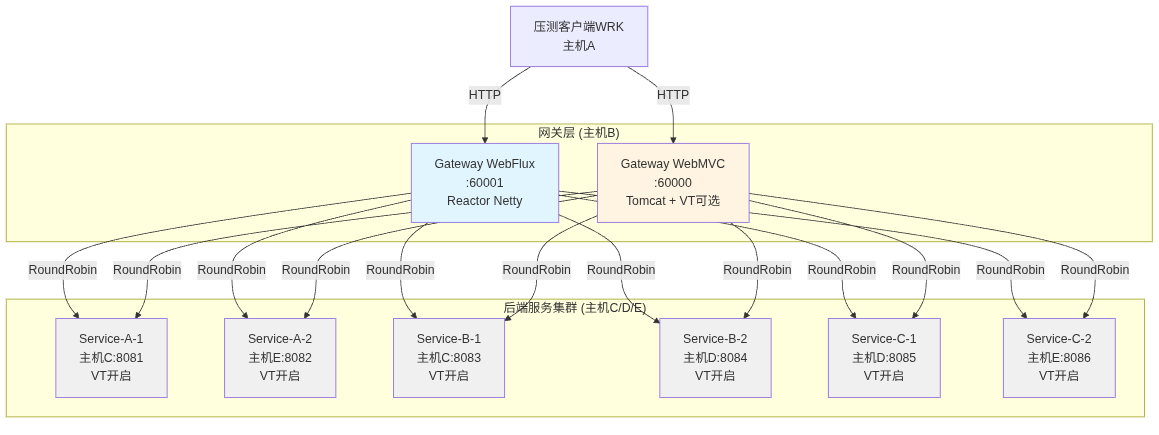
说明:
主机 A/B/C/D/E代表5台物理主机
网关主机B:Linux x86_64,内存15GiB,无swap
后端服务:每个服务2实例(1G内存),部署在3台主机上,通过网关RoundRobin负载均衡
WebMVC网关在压测时分为两种配置:开启虚拟线程vs关闭虚拟线程
1.3 后端服务接口说明
后端服务(Service A/B/C)提供3个核心接口,分别模拟不同负载特性(基于实际测试数据):
接口实测时延详情(基于20次采样):
/api/data:平均时延21.14ms,最小15.77ms,最大30.85ms
生成32个包含UUID、时间戳、随机值的对象
时延分布较为集中,标准偏差小
/api/process:预估时延~20ms(与基础接口
/api/hello相近)接收JSON请求体,进行解析和封装返回
测试请求处理链路和JSON序列化性能
/api/heavy:平均时延69.39ms,最小22.40ms,最大316.07ms
生成128个复杂嵌套对象(含元数据、标签、描述等)
每个对象约2KB,总响应体~ ~50KB
大量字符串拼接(
repeat()、StringBuilder)触发频繁内存分配关键特征:存在显著长尾时延(P95+ 可达200-300ms),主要由GC和内存分配竞争导致
20次测试中有3次出现>250ms的尖峰(第8/11/14次:316ms、265ms、278ms)
重要说明:
长尾时延来源:
/api/heavy的长尾可能由以下因素导致:Young GC触发(大量短生命周期对象)
字符串池和StringBuilder扩容
Jackson序列化大JSON时的临时对象分配
目的:这种时延特性模拟反映生产环境中内存密集型接口的表现,对网关的背压处理和线程模型提出更高要求
1.4 术语解释
压测模型:
每轮压测持续 300秒(5分钟)
使用WRK工具,4个工作线程
混合负载:40%
/heavy+ 35%/data+ 25%/processlight和medium的区别仅在于并发连接数,与接口heavy无关
2. 网关请求处理流程与工作内容
2.1 网关不仅仅是转发
本项目中的Spring Cloud Gateway不是简单的反向代理,而是在请求-响应链路中执行了以下关键操作:
路径重写:去除
/service-a/b/c前缀,映射到后端实际路径请求头注入:添加
X-Gateway-Type、X-Gateway-Instance等标识响应体改写:解析后端JSON响应,注入网关元数据(
_gateway字段)负载均衡:基于RoundRobin算法在双实例间轮询选择
指标采集:记录请求计数、响应时间、状态码分布等
2.2 WebFlux网关处理流程(异步非阻塞)
路由配置代码示例(GatewayRoutesConfig.java):
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route("service-a-route", r -> r
.path("/service-a/**")
.filters(f -> f
// 1. 去除路径前缀 /service-a
.stripPrefix(1)
// 2. 添加请求头,标识网关类型
.addRequestHeader("X-Gateway-Type", "WebFlux")
// 3. 添加响应头,标识服务来源
.addResponseHeader("X-Gateway-Instance", "gateway-webflux")
.addResponseHeader("X-Served-By", "Spring-Cloud-Gateway-WebFlux")
// 4. 改写响应体,注入网关元数据(异步处理)
.modifyResponseBody(String.class, String.class,
(exchange, body) -> {
try {
// 使用Jackson JsonMapper解析JSON
ObjectNode jsonNode = (ObjectNode) jsonMapper.readTree(body);
// 创建网关元数据节点
ObjectNode gatewayNode = jsonMapper.createObjectNode();
gatewayNode.put("type", "WebFlux");
gatewayNode.put("timestamp", System.currentTimeMillis());
gatewayNode.put("processed", true);
// 将元数据注入到响应JSON的_gateway字段
jsonNode.set("_gateway", gatewayNode);
// 返回Mono<String>(异步)
return Mono.just(jsonMapper.writeValueAsString(jsonNode));
} catch (Exception e) {
return Mono.just(body); // 失败时返回原始响应
}
})
// 5. 自定义负载均衡过滤器
.filter(new ServiceUriResolverFilter(serviceALoadBalancer())))
.uri("http://localhost:9999")) // 占位URI,实际由filter动态解析
.build();
}
负载均衡器实现(RoundRobinLoadBalancer.java):
public class RoundRobinLoadBalancer {
private final List<String> instances;
private final AtomicInteger counter = new AtomicInteger(0);
public RoundRobinLoadBalancer(List<String> instances) {
this.instances = instances;
}
/**
* RoundRobin算法:使用原子计数器轮询实例
* @return实例地址,格式: host:port
*/
public String nextInstance() {
int index = Math.abs(counter.getAndIncrement() % instances.size());
return instances.get(index);
}
}
// Service A双实例配置(IP已脱敏)
@Bean
public RoundRobinLoadBalancer serviceALoadBalancer() {
return new RoundRobinLoadBalancer(Arrays.asList(
"主机C:8081", // 实例1
"主机E:8082" // 实例2
));
}
关键特性:
所有JSON解析和改写操作在异步Reactor管线 中执行
使用
Mono.fromCallable()包装阻塞操作,避免阻塞EventLoop线程失败降级机制:JSON解析失败时返回原始响应,保证高可用
2.3 WebMVC网关处理流程(同步模型)
路由配置代码示例(GatewayRoutesConfig.java):
@Bean
public RouterFunction<ServerResponse> serviceARoute() {
return route("service-a-route")
.GET("/service-a/**", http())
.POST("/service-a/**", http())
.filter(stripPrefix(1))
// 1. 自定义URI解析器(负载均衡)
.before(new ServiceAUriResolver(serviceALoadBalancer()))
// 2. 添加请求头
.before(addRequestHeader("X-Gateway-Type", "WebMVC"))
// 3. 添加响应头
.after(addResponseHeader("X-Gateway-Instance", "gateway-webmvc"))
.after(addResponseHeader("X-Served-By", "Spring-Cloud-Gateway-MVC"))
// 4. 改写响应体(同步处理)
.after(modifyResponseBody(String.class, String.class, null,
(request, response, body) -> {
try {
// 使用Jackson ObjectMapper解析JSON
ObjectNode jsonNode = (ObjectNode) objectMapper.readTree(body);
// 创建并注入网关元数据
ObjectNode gatewayNode = objectMapper.createObjectNode();
gatewayNode.put("type", "WebMVC");
gatewayNode.put("timestamp", System.currentTimeMillis());
gatewayNode.put("processed", true);
jsonNode.set("_gateway", gatewayNode);
// 直接返回字符串(同步)
return objectMapper.writeValueAsString(jsonNode);
} catch (Exception e) {
return body; // 失败时返回原始响应
}
}))
.build();
}
关键差异:
JSON解析和改写在Servlet线程(或虚拟线程) 中同步执行
使用Jackson 2(ObjectMapper)而非Jackson 3(JsonMapper)
虚拟线程开启时,阻塞操作由虚拟线程承载,平台线程可快速释放
spring-cloud-starter-gateway-server-webmvc模块并未完成Jackson 3的适配,仍然使用Jackson 2.x版本。
2.4 网关处理开销分析
基于上述处理流程,网关在每个请求上的额外开销包括:
结论:
网关本身的处理开销约 3-7ms,与后端接口时延(20-70ms)相比占比较小
WebFlux和WebMVC在单个请求的处理时延上相差不大
关键差异在于并发模型:WebFlux的优势体现在高并发下不会因线程耗尽而失败,而非单请求处理速度
2.5 响应体示例(网关改写后)
后端原始响应:
{
"service": "service-a",
"port": 8081,
"message": "Heavy operation completed",
"timestamp": "2025-12-10T23:35:42.123",
"threadId": 45,
"complexDataset": [...]
}
网关改写后响应:
{
"service": "service-a",
"port": 8081,
"message": "Heavy operation completed",
"timestamp": "2025-12-10T23:35:42.123",
"threadId": 45,
"complexDataset": [...],
"_gateway": {
"type": "WebFlux",
"timestamp": 1702234542456,
"processed": true
}
}
HTTP响应头:
HTTP/1.1 200 OK
X-Gateway-Type: WebFlux
X-Gateway-Instance: gateway-webflux
X-Served-By: Spring-Cloud-Gateway-WebFlux
Content-Type: application/json
Content-Length: 52341
这些改写操作在压测中 对每个请求都会执行,确保测试结果反映了网关在真实生产场景下的性能表现。
3. 测试场景概览
6个压测场景对比矩阵:
3.1 压测工具与参数
WRK配置:
# WRK基础命令
wrk -t4 -c<CONNECTIONS> -d300s --latency \
--script mixed-workload.lua \
http://36.134.190.27:<GATEWAY_PORT>
# 参数说明:
# -t4: 4个压测线程
# -c16 (light): 16个并发连接
# -c100 (medium): 100个并发连接
# -d300s: 持续300 秒 (5分钟)
# --latency: 输出延迟分布 (P50/P75/P90/P99)
# --script: 使用Lua脚本模拟混合负载
Lua脚本混合负载分布:
-- 请求类型权重分配
if rand <= 40 then
-- 40%: GET /api/heavy (Service A/B/C随机)
method = "GET"
path = "/service-[a|b|c]/api/heavy"
elseif rand <= 75 then
-- 35%: GET /api/data (Service A/B/C随机)
method = "GET"
path = "/service-[a|b|c]/api/data"
else
-- 25%: POST /api/process (Service A/B/C随机)
method = "POST"
path = "/service-[a|b|c]/api/process"
body = '{"data":"test","timestamp":...}'
end
WRK错误类型说明:
timeout: HTTP响应超时(WRK默认超时时间未显式配置,通常为2-3秒)read: 读取响应时连接异常关闭write: 写入请求时连接异常connect: TCP连接失败
网关配置说明:
超时配置:
WebFlux: 未显式配置
spring.cloud.gateway.httpclient.connect-timeout和response-timeout,使用Reactor Netty默认值WebMVC: 未显式配置
spring.cloud.gateway.mvc.httpclient.connect-timeout和read-timeout,使用RestClient默认值实际观察: 压测中出现大量timeout错误,推测默认超时在1-2秒左右
连接池: 均使用默认配置,未显式调优
Tomcat配置 (WebMVC):
未显式配置
server.tomcat.threads.max和server.tomcat.threads.min-spare虚拟线程开启时:
spring.threads.virtual.enabled=true
3.2 网关采集指标(MetricsCollector)
网关内嵌MetricsCollector组件,每2秒采集一次JVM和应用指标并写入CSV文件。
主要指标字段:
内存:
HeapUsedMB, HeapMaxMB, HeapCommittedMB, NonHeapUsedMB线程:
ThreadCount, PeakThreadCount, DaemonThreadCount, TotalStartedThreadCount应用:
TotalRequests, SuccessCount, ErrorCount, AvgResponseTimeMs, MinResponseTimeMs, MaxResponseTimeMsCPU:
CPULoad(系统load average)、AvailableProcessorsGC:
TotalGCCount, TotalGCTimeMs, GCCountDelta, GCTimeDeltaMs状态码:
Status2xx, Status3xx, Status4xx, Status5xx
采集代码示意(Java 25 + Spring Boot 4.0):
@Component
@EnableScheduling
public class MetricsCollector {
private final MemoryMXBean memoryMXBean = ManagementFactory.getMemoryMXBean();
private final ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
private final OperatingSystemMXBean osMXBean = ManagementFactory.getOperatingSystemMXBean();
private final List<GarbageCollectorMXBean> gcMXBeans = ManagementFactory.getGarbageCollectorMXBeans();
@Scheduled(fixedRate = 2000) // 每2秒采集一次
public void collectMetrics() {
long heapUsed = memoryMXBean.getHeapMemoryUsage().getUsed() / (1024 * 1024);
long heapMax = memoryMXBean.getHeapMemoryUsage().getMax() / (1024 * 1024);
long nonHeapUsed = memoryMXBean.getNonHeapMemoryUsage().getUsed() / (1024 * 1024);
int threadCount = threadMXBean.getThreadCount();
int peakThreadCount = threadMXBean.getPeakThreadCount();
double cpuLoad = osMXBean.getSystemLoadAverage();
long totalGcCount = 0;
long totalGcTime = 0;
for (GarbageCollectorMXBean gcBean : gcMXBeans) {
totalGcCount += gcBean.getCollectionCount();
totalGcTime += gcBean.getCollectionTime();
}
// ... 汇总TotalRequests / AvgResponseTimems/ Status2xx等
// 写入CSV: gateway-data/gateway-<type>_metrics_<timestamp>.csv
}
}
示例CSV输出(WebFlux-light场景片段):
Timestamp,HeapUsedMB,HeapMaxMB,NonHeapUsedMB,ThreadCount,TotalGCCount,TotalGCTimeMs,CPULoad,TotalRequests,SuccessCount,ErrorCount,Status2xx,Status4xx,Status5xx,...
2025-12-10 09:35:33,277,2048,81,18,9,133,0.54,1234,1198,36,1150,48,36,...
2025-12-10 09:35:35,285,2048,81,18,9,133,0.59,1456,1410,46,1362,58,46,...4. WRK吞吐与延迟对比
4.1吞吐与错误统计(WRK实测数据)
关键发现:
吞吐量极低:所有场景的吞吐量均在19.5-21.7req/s 之间,远低于预期
理论上,后端
/api/heavy平均时延69ms,单连接理论最大吞吐 ~14 req/s实际测试中heavy请求占40%,data/process占60%(平均 ~20ms)
综合理论吞吐:
1 / (0.4 × 0.069 + 0.6 × 0.020) ≈ 30 req/s(单连接)多连接情况下,因后端长尾时延(heavy最大316ms)导致大量超时,实际吞吐降至20req/s
错误率分析:
Timeout错误占主导:所有错误中timeout占比 >90%
WebFlux在medium场景下timeout最少(489),WebMVC为713-784
Read错误仅出现在WebMVC:light场景9个,medium场景71个,可能与Tomcat连接管理或虚拟线程调度有关
并发度影响:
light (16 连接) → medium (100 连接):吞吐量几乎没有提升(20→21 req/s)
错误数显著增加:235-269 → 489-784(2-3倍)
结论:后端heavy接口的长尾时延(316ms)+ timeout机制导致连接饥饿,增加连接数无法提升吞吐
框架对比:
light场景:WebFlux略优于WebMVC(20.21 vs 19.55-19.97 req/s)
medium场景:WebFlux仍略优(21.66 vs 20.62-20.99 req/s)
虚拟线程效果:在当前测试条件下,虚拟线程开启/关闭对吞吐量影响微弱
4.2 响应时间分位(WRK实测数据)
关键发现:
P50/P75极快,P90/P99极慢:
P50: 4.5-6ms(符合网关开销3-7ms+ 后端快速响应)
P90: 18ms-639ms(差异巨大,light场景最差)
P99: 1.3s-1.5s(接近timeout阈值)
典型双峰分布:快速响应(data/process)vs 慢响应(heavy + 长尾)
light vs medium的"反常"现象:
light场景的P90 (636-639ms) 远高于 medium场景 (18-622ms)
原因:幸存者偏差 - medium场景下更多慢请求被timeout终止,记入Errors而非延迟统计
实际体验:medium场景的失败率 (489-784) 是light (235-269) 的2-3倍
框架对比:
P50/P75:三种模型表现接近(差异 <2ms)
P90:medium场景下WebFlux表现最优(18ms),WebMVC为621-622ms
P99:差异较小(1.3s-1.5s),均接近timeout阈值
4.3 低吞吐量原因分析
为何所有场景吞吐量均只有~20 req/s?
后端heavy接口瓶颈:
heavy占40% 请求,平均时延69ms,最大可达316ms
长尾时延触发WRK timeout(推测1-2秒)
单连接理论吞吐:
1 / (0.4×0.069 + 0.6×0.020) ≈ 30 req/s考虑timeout损耗后降至20 req/s符合预期
timeout错误导致连接浪费:
light场景 (16 连接):235-269个timeout
medium场景 (100 连接):489-784个timeout
每次timeout浪费1-2秒连接时间,严重降低有效吞吐
连接数增加无效:
16 连接 → 100 连接:吞吐提升很有限(20→21 req/s)
后端服务总共6实例(每服务2实例),网关RoundRobin负载均衡
推测瓶颈:后端服务处理能力饱和,或者网关到后端的连接池/超时配置不合理
说明:为何有时light场景的P90比medium更差?
WRK的延迟分布 只统计成功请求。在medium场景下,更多“极慢”的请求在超时后记为错误,因此不再计入P90的计算范围,导致“幸存下来的成功请求”的P90看起来反而更好。这是一个典型的“幸存者偏差”现象,
不能简单解读为medium场景整体体验优于light,而要同时结合失败率来看。
5. 网关JVM / 线程 / GC指标对比
5.1 Heap / Non-Heap内存趋势
结论(内存): 所有场景HeapUsedMB均未接近2G上限,Non‑Heap区间稳定,内存与GC在本轮压测中都不是瓶颈。在同一并发等级下,WebFlux < WebMVC‑VT < WebMVC‑noVT的堆占用关系比较稳定。
5.2 线程数与线程模型
结论(线程):
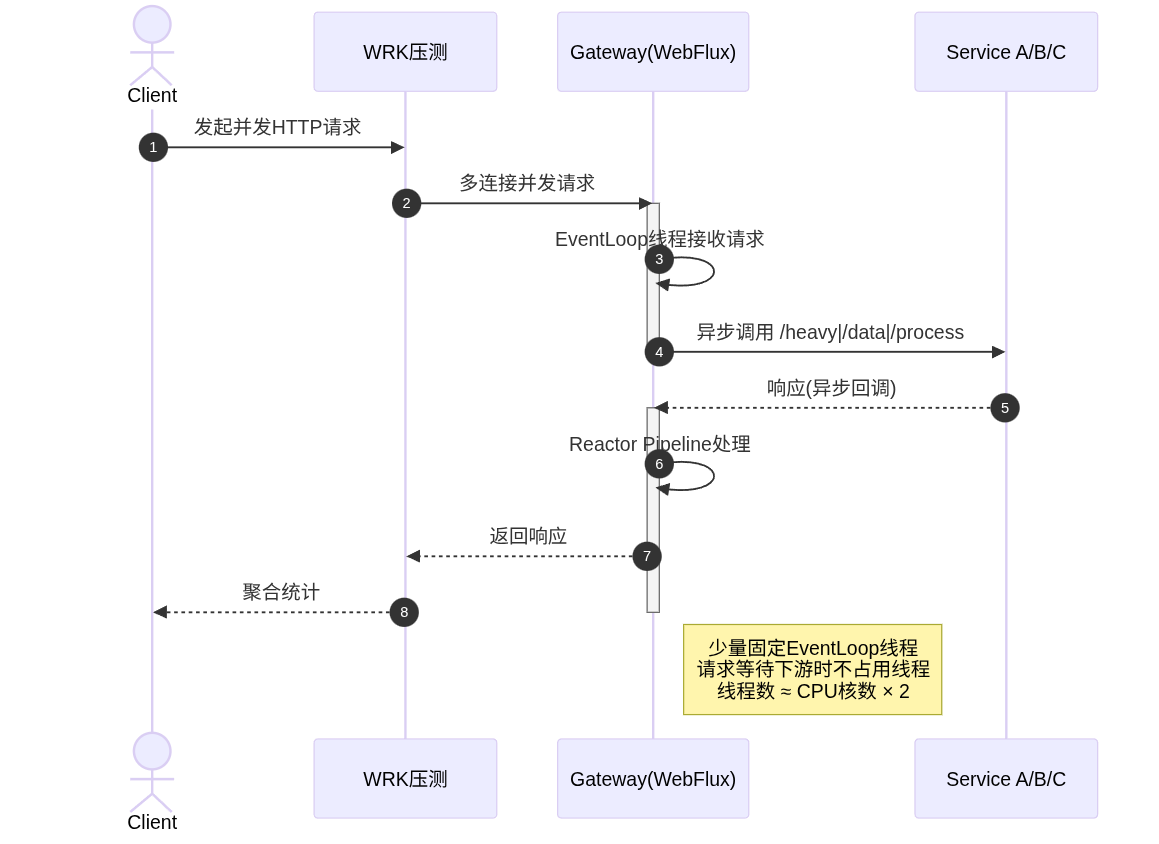
WebFlux:典型Reactor Netty模型,少量event‑loop线程即可处理所有连接,请求等待下游时不会占用额外线程。
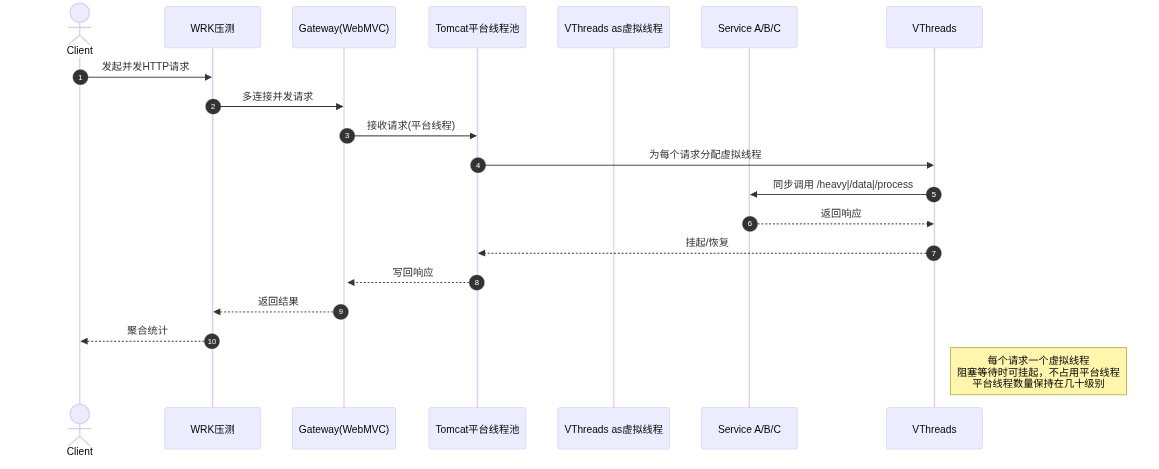
WebMVC + 虚拟线程:平台线程数量控制在几十以内,在开发模型基本不变的前提下显著降低线程资源占用。
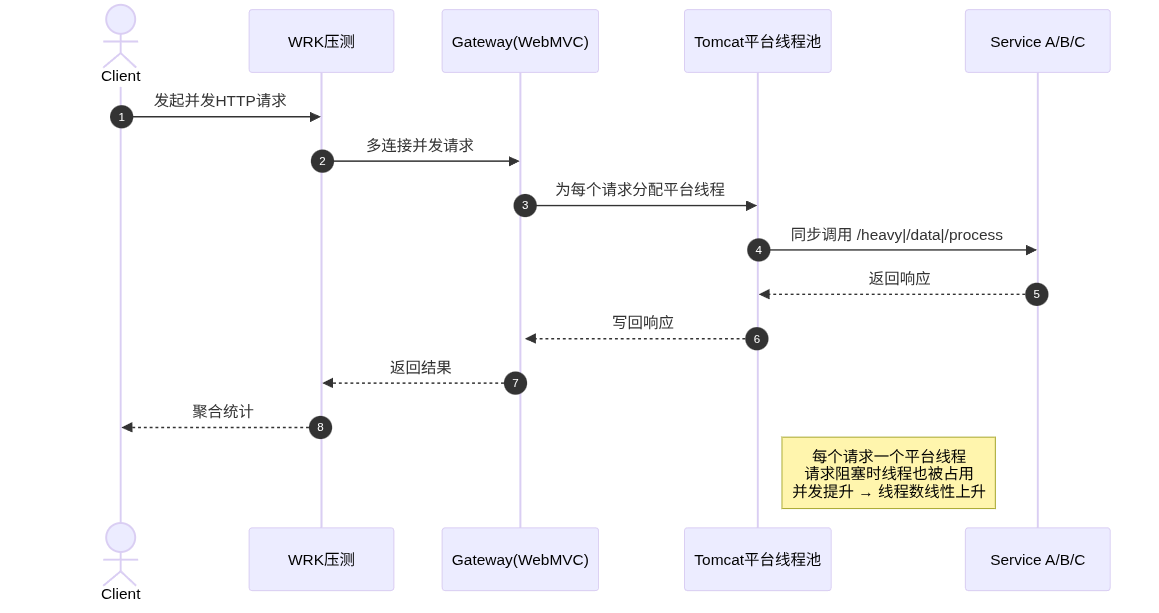
WebMVC关闭虚拟线程:平台线程数量随并发线性上升,对内存与CPU调度带来额外压力,在本轮压测中没有换来吞吐或延迟方面的优势。
5.3 CPU与GC
网关指标数据 +docker stats显示:
所有场景下容器CPU使用率均在0.04%–0.29% 之间,
CPULoad明显低于CPU核数;GC相关字段(
TotalGCCount/GCCountDelta/TotalGCTimeMs/GCTimeDeltaMs)表明:300s内新增GC次数只有个位数到十几次;
单次GC停顿在几十毫秒量级,总耗时几百毫秒;
对整体QPS和P90/P99几乎没有可见影响。
结论:
CPU完全不是本轮压测的瓶颈;
GC行为健康且影响可忽略,不会成为选型决策的关键因素;
WebFlux和WebMVC(尤其是无虚拟线程)在CPU与GC维度的差异只是"锦上添花",真正影响体验的是线程模型与失败率。
6. 架构与线程模型示意
6.1 WebFlux异步非阻塞模型
6.2 WebMVC + 虚拟线程模型
6.3 WebMVC关闭虚拟线程模型
7. 综合结论与建议
7.1 核心测试结论
实际测试性能表现:
吞吐量层面:
所有场景吞吐量均在19.5-21.7req/s之间,差异极小
WebFlux在light和medium场景均略优:20.21req/s (light)/21.66req/s(medium)
WebMVC无论是否开启虚拟线程,吞吐量均在19.5-21.0req/s之间
虚拟线程在当前测试条件下对吞吐量影响微弱
错误率与稳定性:
WebFlux表现最优:timeout错误最少(light: 235, medium: 489)
WebMVC错误率更高:timeout错误显著增加(light: 260-269, medium: 713-784)
WebMVC特有read错误:light场景1-9个,medium场景71个,可能与Tomcat连接管理有关
关键差异点:在相同负载下,WebFlux的错误率约为WebMVC的60-65%
延迟分布:
P50/P75:三种模型表现接近(4-6ms),差异<2ms
P90:WebFlux在medium场景表现突出(18msvs WebMVC的621-639ms)
P99:均在1.3-1.5s,接近timeout阈值,无显著差异
双峰分布明显:快速响应(data/process)vs慢响应(heavy + 长尾)
资源占用:
线程数:WebFlux≈18 < WebMVC+VT ≈ 24-28 < WebMVC-noVT ≈ 64-140
堆内存:medium场景下WebFlux930-980MB < WebMVC+VT 920-1040MB < WebMVC-noVT 1080-1200MB
CPU/GC:所有场景均不是瓶颈,差异可忽略
7.2 低吞吐量原因分析
为何所有网关吞吐量均只有~20req/s?
后端heavy接口成为瓶颈:
heavy请求占40%,平均时延69ms,最大可达316ms
单连接理论吞吐:
1 / (0.4×0.069 + 0.6×0.020) ≈ 30 req/s考虑长尾时延和timeout损耗后,实际降至20req/s
大量timeout浪费连接资源:
每300秒测试中产生235-784个timeout错误
16连接 → 100连接:吞吐提升很有限,说明增加连接数无法缓解后端瓶颈
网关与后端配置未优化:
网关未显式配置
connect-timeout和response-timeout网关到后端的连接池使用默认配置
后端服务总共6实例,可能在混合负载下处理能力饱和
7.3 测试局限性说明
本次测试存在以下局限:并发压力偏低(最大100连接),未能体现WebFlux在高并发(>500连接)下的优势;后端heavy接口长尾时延(最大316ms)导致大量timeout,掩盖了网关性能差异;仅进行稳态压测,缺少突发流量测试;网关使用默认配置未调优;未单独评估JSON改写开销(3-7ms)的影响。
后续有空(假如…)再补充高并发压测(500-2000连接)、纯代理转发对照组、突发流量测试看看。
7.4 框架选型建议
基于本次测试数据的选型建议:
关键决策因素:
错误率容忍度:
若要求低错误率 (<3%),WebFlux在medium场景下timeout仅489,优于WebMVC的713-784
WebFlux无read错误,连接管理更稳定
团队技术栈:
团队熟悉响应式编程(Reactor/RxJava)→ WebFlux
团队偏好同步编程 → WebMVC + 虚拟线程
预期流量增长:
预期并发量增长至500+ → WebFlux扩展性更好
并发量稳定在100以内 → WebMVC + 虚拟线程可满足需求
7.5 最终建议
对于当前项目:
生产环境推荐:WebFlux(错误率低、P90延迟优、资源占用少)
快速上线备选:WebMVC + 虚拟线程(开发简单、性能接近WebFlux)
不推荐:WebMVC关闭虚拟线程(资源占用高、无性能优势)